# 3 程序的机器表示
# Intel 系列芯片发展历史
-- 该部分可略过
- 8086 (1978)
它是第一代 16 位 微处理器之一.
8088 是 8086 的变种增加了一个 8 位的外部总线 可寻址地址空间仅有 20 位
8087 是 Intel 设计出的浮点协处理器,与 8086 或 8088 一同工作用于执行浮点指令,通常被称为x87 - 80286 (1982)
增加了更多的寻址模式 (已废弃), 构成了 IBM PC-AT 个人计算机的基础,是 MS Windows 最初使用的平台 - i386 (1985)
将结构体系拓展到了 32 位。增加了平坦寻址模式,Linux和 最近的Windows操作系统都采用了这种模式。这是Intel系列中第一台支持Unix操作系统的机器 - i486 (1989)
改善了性能,同时将浮点单元集成到了处理器芯片,指令集上没有任何改变 - Pentium (1993)
改善了性能,不过只对指令集进行了小的扩展 - Pentium Pro (1995)
引入全新的全新的处理器设计,在内部被称为 P6 微体系结构.
指令集中增加了一类 "条件传送 (conditional move)" 指令 - Pentium/MMX (1997)
在Pentium处理器中增加了一类新的处理整数向量的指令。每个数据大小可以是 1,2 或 4 个字节。每个向量总长 64 字节 - Pentium II (1997)
P6 微体系结构的延伸 - Pentium III (1999)
引入 SSE, 是一类处理整数或浮点数向量的指令.
每个数据可以是 1, 2 或 4 字节,打包成 128 位的向量.
芯片上集成了二级高级缓存 - Pentium 4 (2000)
SSE 扩展到了 SSE2, 增加了新的数据类型 (包括双精度浮点), 以及针对这种格式的数据的 114 条指令,编译器可以使用这些指令来编译浮点代码 (可替代 x87) - Pentium 4E (2004)
增加了超线程 (hyperthreading), 使得一个处理器上可以同时运行两个程序
增加了 EM64T, 它是Intel对AMD提出的IA32的 64 位扩展的实现,被称为x86-64 - Core 2 (2006)
回归到了 P6 的微体系结构.Intel的第一个多核微处理器,不支持超线程 - Core i7 Nehalem (2008)
支持超线程,也有多核,最初的版本支持每个核上可以执行两个程序 - Core i7 Sandy Bridge
引入了AVX, 这是对SSE的拓展,支持把数据封装 256 位的向量 - Core i7 Haswell
将 AVX 扩展至AVX2, 增加了更多的指令和格式
# 程序编码
C 语言到可执行文件需要经历四步:
1. 预处理
代码拓展,将所有 宏和头文件 加入源代码
2. 编译
生成 .c 文件的 .s 文件
3. 汇编
将 .s 文件生成 .o(二进制目标代码文件) 文件
4. 链接
将 .o 文件按一定格式连接在一起 生成一个 CPU 可执行的文件
# 机器代码
- ISA: 指令集架构
它定义了 处理器状态,指令集格式 及每条指令执行完毕之后对状
态的影响- 虚拟地址:机器程序使用的地址
# 代码示例
相关代码文件都在 3_2 文件夹中
{}执行命令
gcc -Og -S mstore.c可以 得到 mstore.s
执行命令gcc -Og -c mstore.s可以 得到 mstore.o
执行命令objdump -d mstore.o可以 得到 mstore.o 的反汇编
(在 3_2 内 makefile 文件内有相关指令)
# 数据格式
| C 声明 | Intel 数据类型 | 汇编代码后缀 | 大小 (字节) |
|---|---|---|---|
| char | 字节 | b | 1 |
| short | 节 | w | 2 |
| int | 双字 | l | 4 |
| long | 四字 | q | 8 |
| char* | 四字 | q | 8 |
| float | 单精度 | s | 4 |
| double | 双精度 | l | 8 |
汇编使用后缀 l 来表示 int 和 k'l 并不冲突二者采用不同的指令和寄存器
# 访问信息
一个 x86-64 的包含 16 个存储 64 位值的 通用数据寄存器,如下表
所有寄存器以 %r 开头.
从 %ax - %sp 是 8086 时期的 寄存器
从 %eax - %esp 是 IA32 时引入的
从 %r8 - %r15 是 x86-64 引入的
对于寄存器操作:对于寄存器操作生成小于 8 字节的操作有以下规定 1-2 字节保持不变,生成 4 字节会将高位置 0
| 64 | 32 | 16 | 8 | 作用 |
|---|---|---|---|---|
| %rax | %eax | %ax | %al | 返回值 |
| %rbx | %ebx | %bx | %bl | 被调用者保存 |
| %rcx | %ecx | %cx | %cl | 第四个参数 |
| %rdx | %edx | %dx | %dl | 第三个参数 |
| %rsi | %esi | %si | %sil | 第二个参数 |
| %rdi | %edi | %di | dil% | 第一个参数 |
| %rbp | %ebp | %bp | %bpl | 被调用者保存 |
| %rsp | %esp | %sp | %spl | 栈指针 |
| %r8 | %r8d | %r8w | %r8b | 第五个参数 |
| %r9 | %r9d | %r9w | %r9b | 第六个参数 |
| %r10 | %r10d | %r10w | %r10b | 调用者保存 |
| %r11 | %r11d | %r11w | %r11b | 调用者保存 |
| %r12 | %r12d | %r12w | %r12b | 被调用者保存 |
| %r13 | %r13d | %r13w | %r13b | 被调用者保存 |
| %r14 | %r14d | %r14w | %r14b | 被调用者保存 |
| %r15 | %r15d | %r15w | %r15b | 被调用者保存 |
# 操作数指示符
汇编指令大多数都有一个或多个操作符,一般来说操作符可以分为三种
- 立即数
- 寄存器
- 内存引用

PS: 基址 和 变址 都必须是 64 位的寄存器
# 数据传输指令
# 基本数据传送指令
| 指令 | 效果 | 描述 |
|---|---|---|
| MOV S, D | D <- S | 传送 |
| movb | 传送字节 | |
| movw | 传送节 | |
| movl | 传送双节 | |
| movq | 传送四节 | |
| movb I, R | 传送绝对的四节 |
# 扩展传送指令
| 指令 | 效果 | 描述 |
|---|---|---|
| MOVZ | R <- 零扩展 (s) | 以 0 进行扩展传送 |
| movzbw | 将做了 0 扩展的字节传送到字 | |
| movzbl | 将做了 0 扩展的字节传送到双字 | |
| movzwl | 将做了 0 扩展的字传送的双字 | |
| movzbq | 将做了 0 扩展的字节传送到四字 | |
| movzwq | 将做了 0 扩展的字传送到四字 |
# 符号扩展传送指令
| 指令 | 效果 | 描述 |
|---|---|---|
| MOVS | R <- 符号扩展 (s) | 传送符号扩展字节 |
| movsbw | 将做了 符号 扩展的字节传送到字 | |
| movsbl | 将做了 符号 扩展的字节传送到双字 | |
| movswl | 将做了 符号 扩展的字传送的双字 | |
| movsbq | 将做了 符号 扩展的字节传送到四字 | |
| movswq | 将做了 符号 扩展的字传送到四字 | |
| cltq | 把 %eax 符号 扩展到 %rax | |
# 数据传送示例
交换两个数,不错的思路,减少一个 动态指针
C 代码位于 3_4_# 中,ASM 代码位于 3_4_3/ASM 中
{}
反汇编
0000000000000000 <exchange>: 0: 8b 01 mov (%rcx),%eax 2: 89 11 mov %edx,(%rcx) 4: c3 retq
# 数据入栈和出栈
栈,数据类型的一种,FILO 只从顶部进出数据,只有两种操作 pop 和 push
指令 效果 描述 pushq S R[%rsp] <- R[%rsp]-8; 将四字压入栈 M[ R[%rsp]] <- S popq S D <- M[ R[%rsp]]; 将四字压入栈 R[%rsp] <- R[%rsp]+8 PS: 由于与数据代码共用一片内存,栈空间也可以直接,寻址访问
# 算数逻辑操作
操作符被分为四种
- 加载有效地址
- 一元操作符
- 二元操作符
- 移位
相关指令如下:
| 指令 | 效果 | 描述 | |
|---|---|---|---|
| leaq S, D | D <- &S | 加载有效地址 | |
| INC D | D <- D+1 | 自加 | |
| DEC D | D <- D-1 | 自减 | |
| NEG D | D <- -D | 取负 | |
| NOT D | D <- ~D | 取补 | |
| ADD S, D | D <- D+S | 加 | |
| SUB S, D | D <- D-S | 减 | |
| IMUL S, D | D <- D*S | 乘 | |
| XOR S, D | D <- D^S | 异或 | |
| AND S, D | D <- D&S | 与 | |
| OR S, D | D <- D | S | 或 |
| SAL k, D | D <- D << k | 左移 | |
| SHL k, D | D <- D << k | 左移 (等同于 SAL) | |
| SAR k, D | D <- D >> k | 算数右移 | |
| SHR k, D | D <- D >> k | 逻辑右移 |
# 加载有效地址
leaq 命令用于传送有效地址,是 mov 指令的一个变种,类似于 C 语言中的 & 的运算符。该指令和加载引用内存无关,一般用于简化 运算符.
| 指令 | 效果 | 描述 |
|---|---|---|
| leaq S, D | D <- &S | 加载有效地址 |
例如:
设%rdx为 x , 那么 指令leaq 7(%rdx, %rdx, 4), %rax加载的 %%rax寄存器最终的值为5x+7
# 一元和二元操作
# 一元操作
指令 效果 描述 INC D D <- D+1 自加 DEC D D <- D-1 自减 NEG D D <- -D 取负 NOT D D <- ~D 取补
# 二元操作
指令 效果 描述 ADD S, D D <- D+S 加 SUB S, D D <- D-S 减 IMUL S, D D <- D*S 乘 XOR S, D D <- D^S 异或 AND S, D D <- D&S 与 OR S, D D <- D S 或
# 移位操作
移位量可以是一个 立即数,或者单字节寄存器 %cl 中。对于 x86-64 位移量取决于 %cl 的低 m 位决定的,2^m = w (w 为被操作数据的位数). 例如: %rcl = 0xff 时, salb 左移 7 位, salw 左移 15 位, sall 左移 31 位, salq 左移 63 位.
指令 效果 描述 SAL k, D D <- D << k 左移 SHL k, D D <- D << k 左移 (等同于 SAL) SAR k, D D <- D >> k 算数右移 SHR k, D D <- D >> k 逻辑右移
PS: 移位操作的目的操作数可以是寄存器 也可以是内存地址
# 分析
相关文件位于 3_5_4 中,不知道什么原因,数据 参数 1 和参数 2 寄存器不可用
大多数运算都是不区分符号,除了右移这个分为两种
# 特殊算数操作
对于两个 64 位的数据运算 x86-64 提供了一定的支持,8 字数据,指令如下
- 对于 64 位乘法,只有一个操作数,但是和 8086 类似 有一个 数据需要存放到
%rax, 得到的结果 分为高低位分别存放在%rdx和%rax中 - 对于除法 提供了单独的
idivl被除数分为高低 64 位分别存放在%rdx和%rax寄存器中,得到的结果 商存放在%rax, 余数存放在%rdx. 除数由操作数给出,使用这个指令时,如果被除数是 64 位,需要将%rdx置 0 或者填充 符号位,可直接使用cqto - ps:
cqto不需要操作数,可以隐含的读出%rax的符号位,并填充到%rdx中
# 控制
机器代码提供两种基本的基地机制来实现有条件的行为:测试数据值,然后根据测试结果来改变 控制流 或 数据流,一般来说流控制最为常用
# 条件码
| 条件码 | 作用 |
|---|---|
| CF | 进位标志。最近的操作使最高位产生了进位。可以用于检查无符号的溢出 |
| ZF | 零标志。最近操作得出结果为 0 |
| SF | 符号标志。最近操作得到的结果为负数 |
| OF | 溢出标志。最近的操作导致一个补码溢出 -- 正溢出 / 负溢出 |
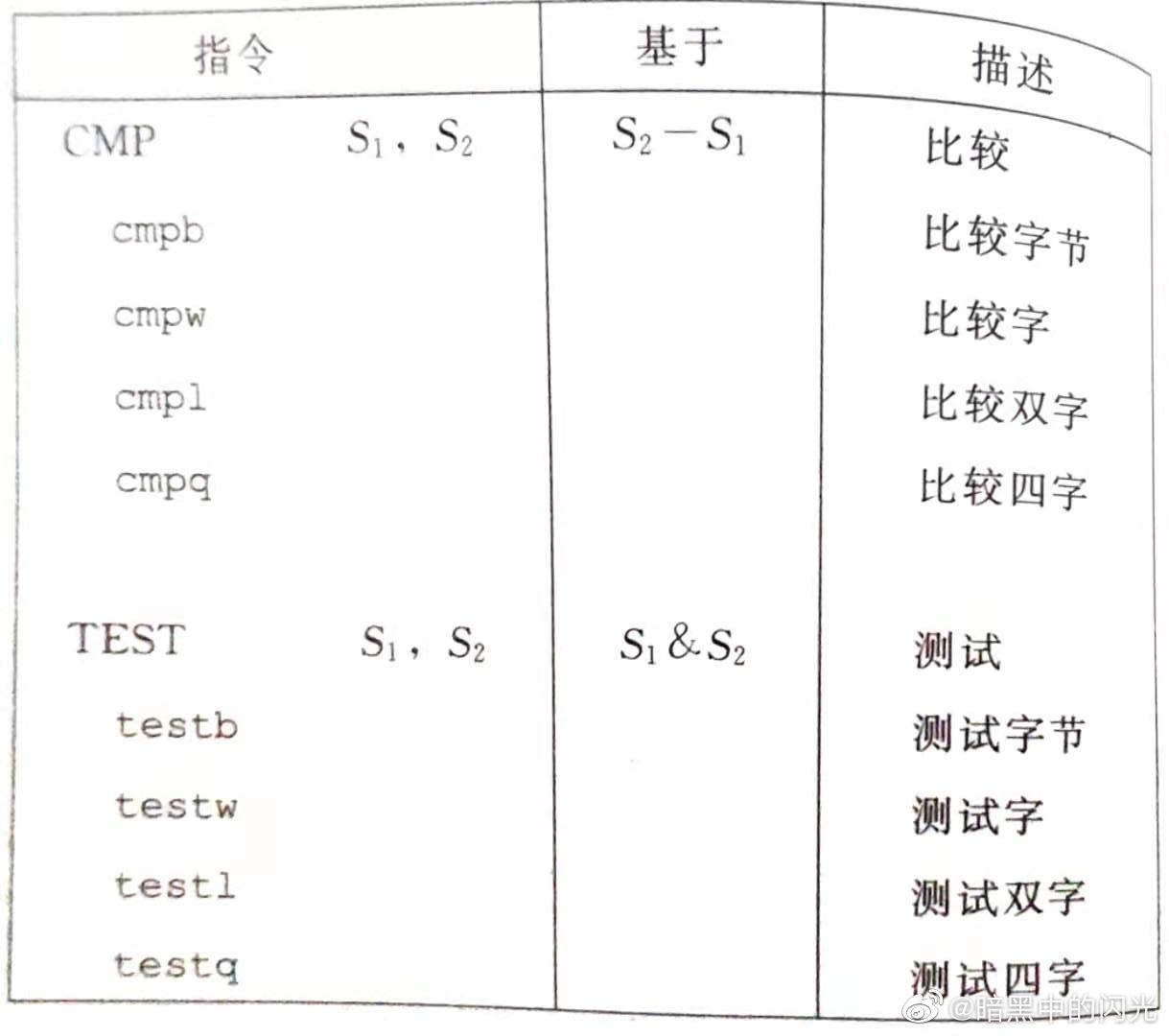
leaq指令 不会修改任何 条件码,INC和DEC不会导致溢出码改变- CMP 和 TEST 指令不改变寄存器值只改变条件码,对应指令如图
![alt test 和 cmp 指令]()
# 访问条件码
条件码一般不会被直接读取,通常采用三种方式来使用:
- 根据条件码的某种组合,将一个字节置 0/1
- 可以转跳到程序的某个其他部分
- 可以有条件的传送数据
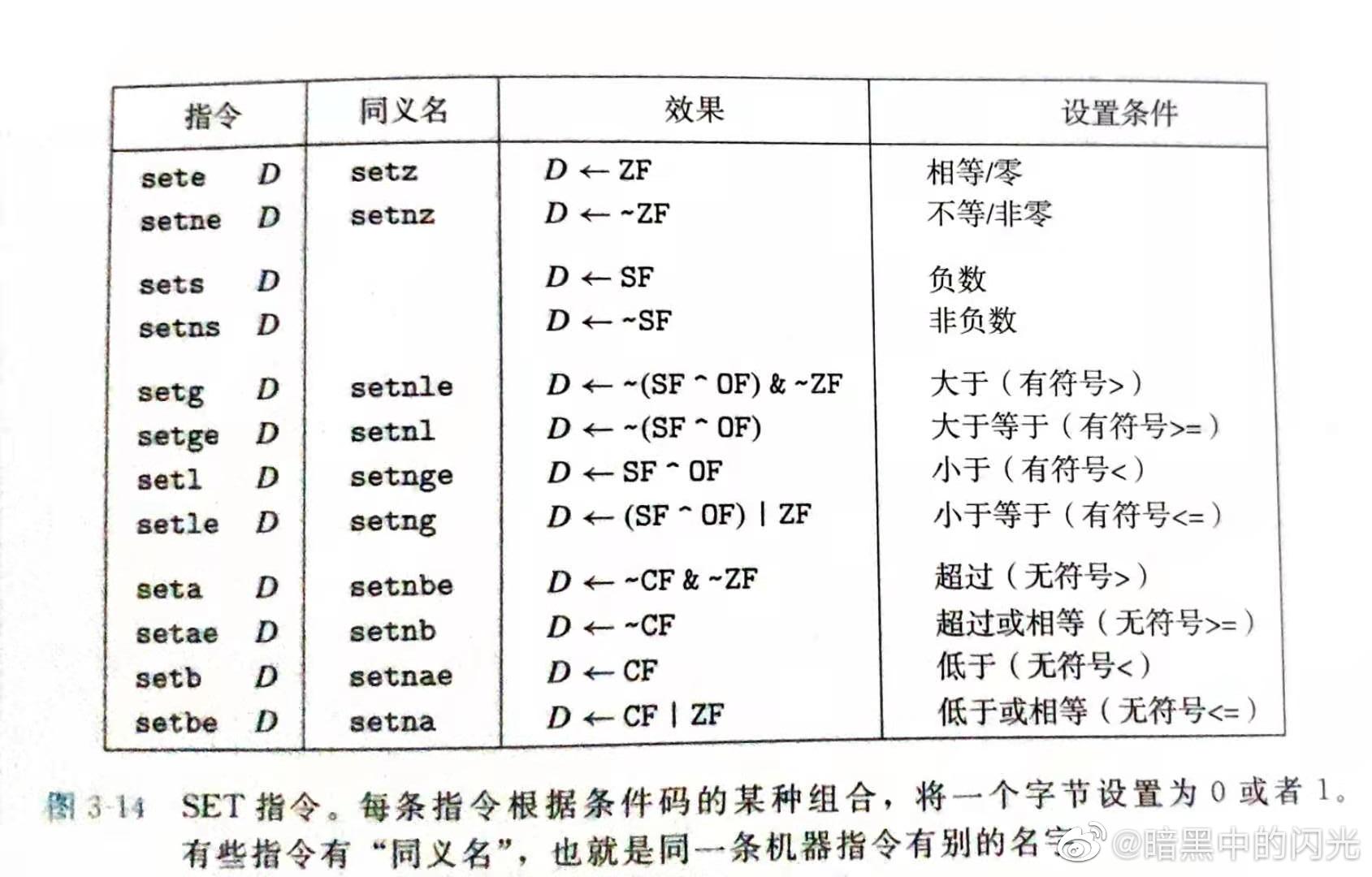
与第一个使用 方法相关的指令为SET, 用于对各种寄存器的高位清零。相关指令如图:![alt set指令]()
PS: SET 只能操作字节
# 跳转指令
jmp 指令可以进行无条件转跳,转跳分为两种
- 直接转跳
jmp 标号,例如jmp .L1 - 间接转跳
jmp *%rax, 例如jmp *%rax
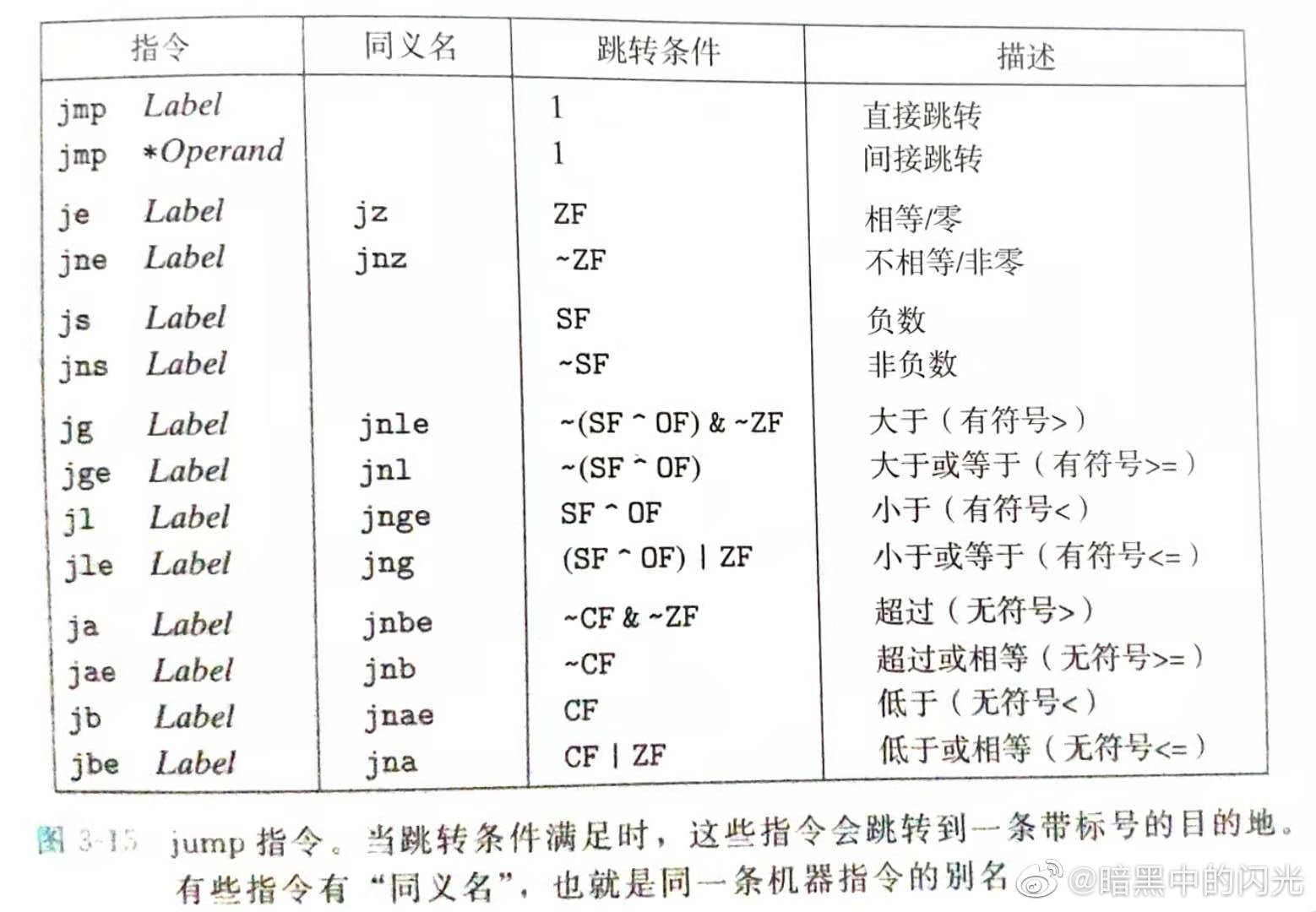
如果需要将 寄存器的值 作为转跳地址这么写jmp *(%rax)jump包括 了jmp和有条件转跳的jxx,jxx是有条件转跳 当条件码到一定时组合时,进行转跳。相关指令如下:![alt jump 指令]()
PS: 条件转跳只能进行直接转跳
# 跳转指令的编码
- 编码分为两种,PC 指针 相对寻址 和 绝对地址
- 绝对地址 一般 为 1, 2, 4 字节中的 其中一个大小
- 大部分转跳都是使用 PC 指针相对转跳,即计算地址与 PC 指针 的差值
- 这部分的编码与链接息息相关
相关习题如下![alt 必会习题]()
指令rep和repz![alt rep和repz关系]()


# 条件控制实现条件分支
相关代码位于 3_6_5
调节表达式从 C 语言翻译为机器码最常用的方式为有条件转跳和无条件转跳相结合
C 语言 if-else 语句格式如下:
if (test_expr) | |
then-statement | |
else | |
else-statement |
对应的 goto 模拟板
t = text_exper; | |
if (!t) | |
goto false; | |
then-statement | |
goto done; | |
false: | |
else-statement | |
done: |
# 条件传送实现条件分支
相关代码位于 3_6_6.
OPItem 为三目运算符编译结果
对于现代处理器 条件转移 (控制流) 十分低效。对于现代的 处理器 来说都采用 流水线 的方式 来提高性能,处理指令需要一系列的指令。当 处理器 遇到 条件指令时就会采用 极其精密的 分支预测逻辑 来猜测执行率,,只要比较可靠,流水线就会开始填充目前指令。但是预测出错就会导致 工作性能严重下降.
相比之下 条件传送 (控制数据) 只有在赋值 的情况下需要 进行判断,生成的汇编代码更加紧凑,执行的效率会更加高效.
其 C 语言格式如下:
v = then_expr; | |
ve = else_expr; | |
t = test_exper | |
if (!t) v = ve; |
在汇编中通过 comv 指令来实现值传送
于其相关的指令如下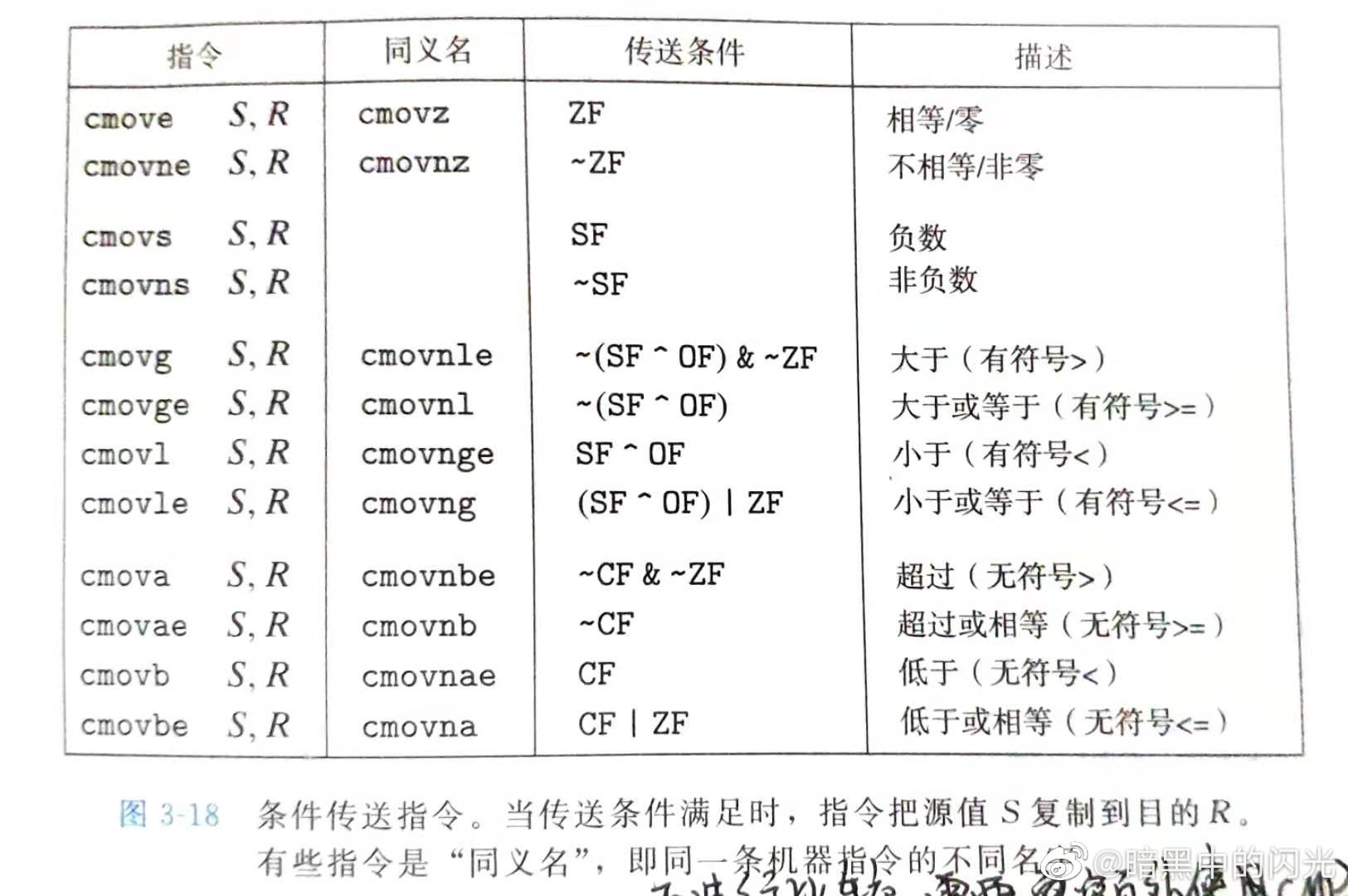
PS: 条件传送不一定必然高效,而且存在 bug
当 传入的值为指针时,不进行检测直接进行运算是十分危险的,而且在需要复杂计算时,采用条件传送会过于浪费时间,条件传送有很多局限性,但其的确最适合 现代处理器的执行方式
# 循环
# do while 循环
相关文件位于 3_6_7.1 中
其 等价 goto 代码 如下
loop: | |
body_statement | |
t = text_exper; | |
if (t) | |
goto loop; |
逆向工程的核心就是确哪个寄存器对应的程序哪个值
# while 循环
相关文件位于 3_6_7.2 中
- while 可能一次循环都不执行
- GCC 采用两种方式来翻译 while, 两种翻译方式只有 初始检测方式不同,循环结构与
do while无异- 转跳到中间 (jump to middle), 一开始会执行一个无条件转跳,跳到循环末尾处的测试,来实现初始检测
goto test;
loop:body_statement
test:t = text_exper;
if (t)
goto loop;
- guraded_do, 最开始使用条件分支,初始条件不成立即跳过循环,将代码转换为
do while格式,使用-O1选项的时候,代码会使用这种方式进行编译
翻译成 do while
t = text_exper;
if (!t)
goto done;
dobody_statement;t = test_exper;
if (t)
goto loop;
done:PS : 采用第二种方式进行翻译时,有些时候 初始判断 会被优化对应的 `goto` 版本t = text_exper;
if (!t)
goto done;
loop:body_statement;t = test_exper;
if (t)
goto loop;
done:
个人感觉 后面这种翻译方式更加高效
# for 循环
相关文件位于 3_6_7.3 中
一般来说 for 循环结构如下
for (init_exper; text_exper; update_exper) | |
body_statement |
在 GCC 中 for 语句 会被转化为 两种 while 语句中的一种 格式大致如下,部分情况会进行微调
jump to middle 版本:
init_exper; | |
goto test; | |
loop: | |
body_statement | |
update_exper; | |
test: | |
t = text_exper; | |
if (t) | |
goto loop; |
guraded_do 版本:
init_exper; | |
t = text_exper; | |
if (!t) | |
goto done; | |
loop: | |
body_statement | |
update_exper; | |
t = text_exper; | |
if (t) | |
goto loop; | |
done: |
# switch 语句
相关文件位于 3_6_8 中,TEST 中为测试 case 生成转跳表所用的文件
switch语句在条件较多的情况下 (一般多余 4 个), 并且 case 值跨度较小的时候会更加高效,在翻译的时候会被翻译成 转跳表switch执行开关语句的时间与开关数量无关&&运算符可以用来指向 代码地址,可以与goto搭配使用实现switch case.rodata表示只读数据,align 4表示 每个数据大小为 4 字 (8 字节)![alt 书本样例]()
不过现在编译出来有些不同![alt 书本样例编译]()


# 过程
过程是一种封装代码的方式,用一组指定的参数 和 可选返回值实现某种功能
实现这种功能的需要以下机器级支持一项或几项:
- 传递控制
- 传递数据
- 分配和释放内存
为了简化讨论,我们把调用函数的过程称为P, 被调用的函数称为fun
# 运行时栈
这里的栈并非抽象概念,是一个实例. C 语言的过程调用就依赖于栈的 FILO 的机制.
如果 P 调用 fun , 那么流程大致如下:
P被挂起,P的数据存入栈中,进行现场保存.- 为
fun的数据 分配空间. fun返回后,释放fun的数据空间- 重新读入
P数据,恢复现场
通用的栈结构:![alt 栈]()
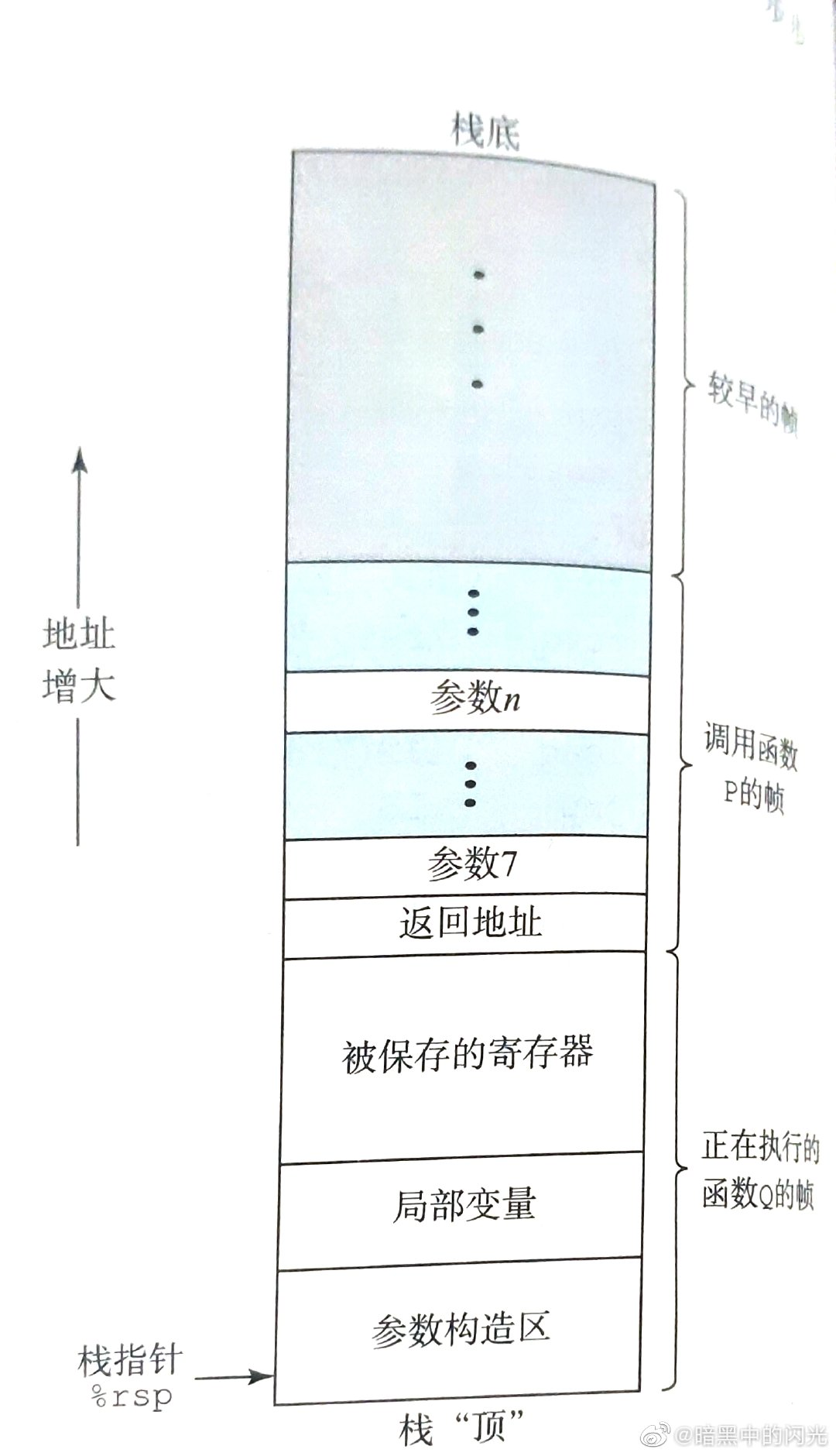
有关 P 的数据只存放在 P 帧内部,返回地址一般会存放在整个帧的最末尾。一次调用最多传送 6 个整数值 (即 6 个 指针或整型), 其他类型或多出的参数会被存放栈帧里。参数构造一般会在调用前执行
# 转移控制
相关的指令如下:
| 指令 | 描述 |
|---|---|
| call Label | 调用过程 |
| call *Operand | 过程调用 |
| ret | 从过程中返回 |
P 调用 fun 时,PC 计数器 被置为 fun 的首地址,返回后 PC 计数器 还原到原来的地址.
图示: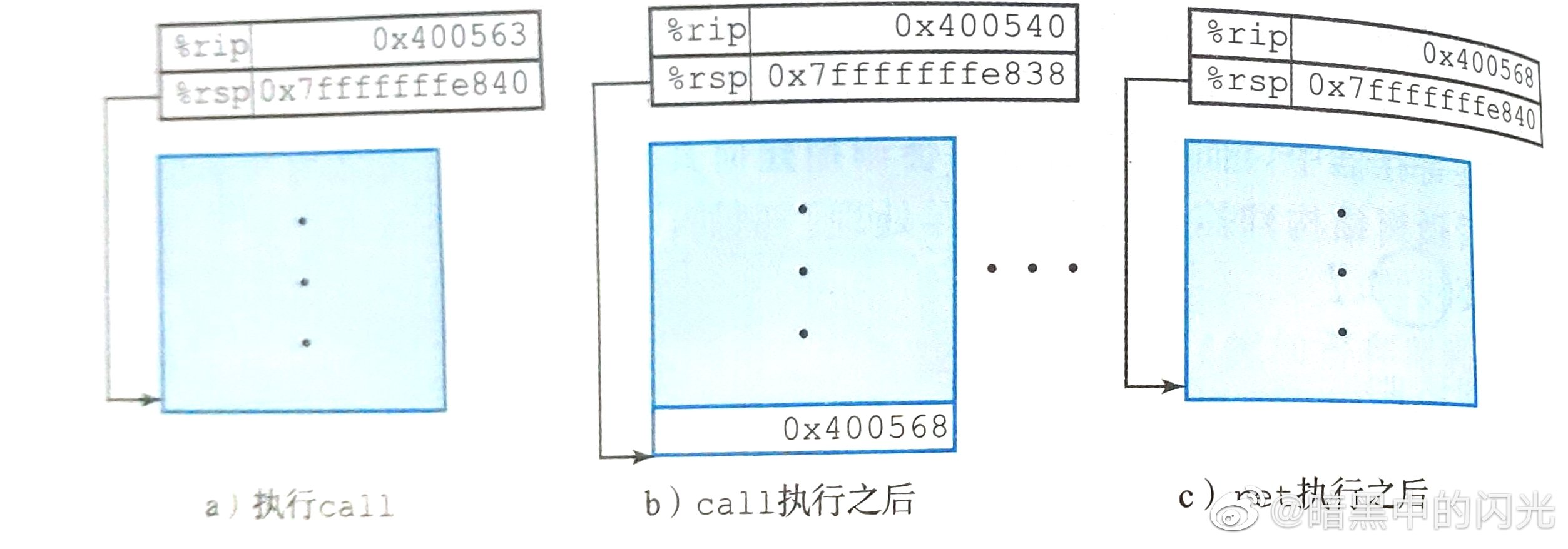
# 数据传送
上面说过,寄存器只有 6 个 是用来保存参数的,那么如果需要传参 > 6 的参数,就需要预先存入栈中.
来看一个例子,分析以下多余的参数是如何在栈中分布的
图片中 a4p 和 a4 转移到 %rax 和 %edx 数据来源于 16(%rsp) 和 8(%rsp) , 所以 多出的参数以 push 操作的正常大小压入栈内,以此类推
所以考虑将使用频率高的参数 提前.
结构体尽可能不要传值,在这也能体现出来,如果不想改变结构体的值,考虑传入一个 const * 指针
# 栈上局部缓存
这里就开始讨论, fun 数据存储的问题了.
目前出现的例子中没有超出寄存器大小的本地存储区域,但是以下这几种情况就需要将局部数据存入内存中:
- 寄存器不足以存放所有本地数据
- 对一个局部变量使用
&, 必须有相应的内存地址给其引用 - 局部变量是结构体或数组.
来看一个例子:



# 寄存器中的局部存储空间
在整个程序执行过程中 只有寄存器是被所有过程共享资源的,所以我们需要时刻注意,在调用其他过程的时候,寄存器的值不被覆盖,或者说如何保存调用前寄存器内部的值
依据惯例:
%rbx、%bpx和%r12~%r15被划分为 被调用者保存寄存器- 除
%rsp以及上面的寄存器 以外的寄存器,都被 称为调用者保存寄存器
来看一个例子: